Run Coding Agents on Local AI — Zero Cloud, Full Control
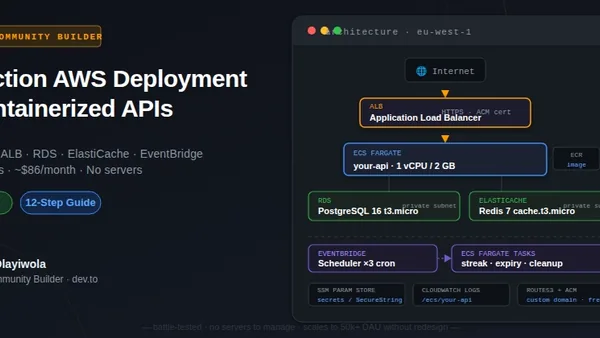
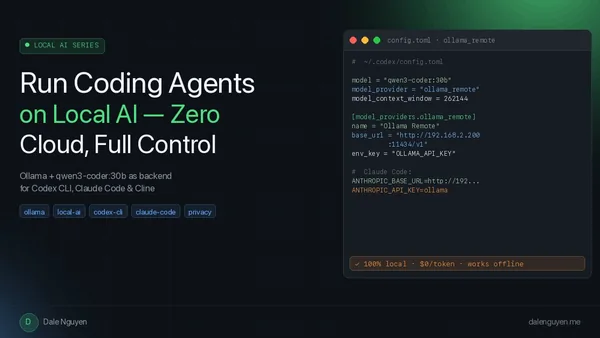
A guide demonstrates replacing cloud-based coding agents (Codex CLI, Claude Code, Cursor) with a local Ollama server running qwen3-coder:30b, achieving zero data exfiltration and no per-token costs. The Mixture-of-Experts model uses only 3.3B active parameters per token, fits in 48 GB unified memory on Apple Silicon, and beats GPT-4o on HumanEval benchmarks with a 256K context window. Configuration requires binding Ollama to 0.0.0.0 and pointing tools at the OpenAI-compatible /v1 endpoint on the LAN IP.